Introduction
The export activity of Yad Vashem had two goals. Firstly, we wanted to update the Yad Vashem content on the EHRI portal, improving the quality of the descriptions and adding a few new records. Secondly, we wanted to prepare the infrastructure to have a sustainable connection to the EHRI portal, allowing content updates and additions of new material on a regular basis.
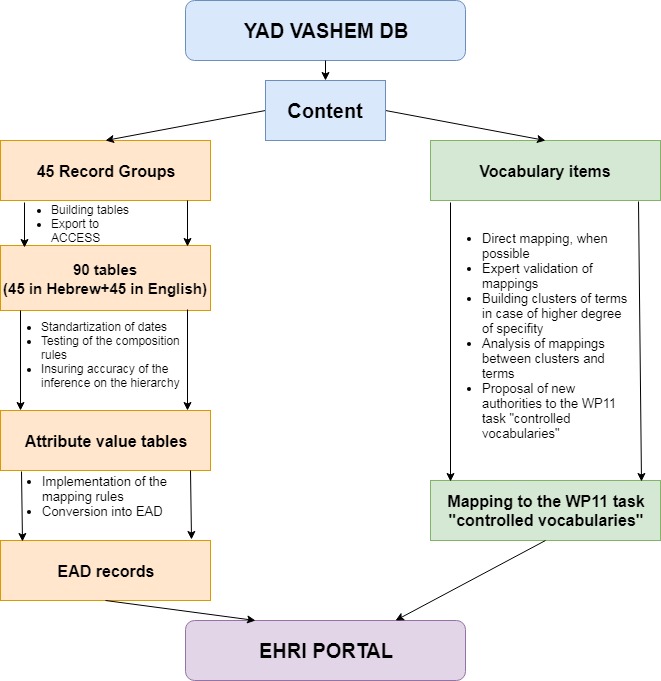
In this activity we exported a total of 45 record groups, which have an internal hierarchical structure. We faced several challenges in the export process, including the definition of the export structure and standardization of the data; development of new workflows while bearing in mind that they should be designed to allow automatization in the future; and the creation of a new service in the Yad Vashem digital infrastructure for publishing data in a sustainable way.
Example of an exported record group from the Yad Vashem Archives in the EHRI portal
In the following sections we present a summary of the designed workflows and a description of the main steps that we took to successfully import the data into the portal.
Definition of Data export
Although most of the data fields to be exported for the EAD correspond to data fields of the Yad Vashem database, additional fields had to be constructed during the export. The most relevant cases are:
- Levels of description, which are not explicitly stored but use a set of rules inside of the system which was defined to construct the hierarchy of the record group as represented in the EAD files
- Archival reference, which was built through concatenation of existing fields
- URL of the metadata record, built using a set of rules
- Scope and content – one of the most challenging examples – involving transformation, merging and data type conversion operations
- Classification and selection of the access points present in each record corresponding to the authority file to which they are linked inside of the system. Lastly, we gave each metadata record a selection and classification by person, organization, location and term.
Finally, we created two separate sets of exported tables:
- Record groups: For each record group we build two tables, one with Hebrew text and a second one with the English translation.
- Vocabulary items: The vocabulary items relevant for the export, including access points of the medata records and creators, were exported for further processing.
Data preprocessing and tests
The tables were exported into an ACCESS database for further processing and testing.
The most relevant preprocessing and testing processes were:
- Normalization/standardization of dates into the ISO format requested by EHRI
- Tests for accuracy in the application of the composition rules and inferences mentioned previously
- Especially relevant was ensuring accuracy of the inference of the hierarchy, after we noted during an experimental setting that one of the tables contained a inconsistent hierarchy that was not detected by the EAD conversion tool (ECT)
Finally, the record group tables were exported as attribute value tables for conversion into EAD.
EAD creation
We used the EAD conversion tool (ECT) provided by EHRI to create the EAD files, since it allows for the creation of the EAD, consistent with the constraints requested by the EHRI project.
The most challenging part of the work was the implementation of the rules to map our data fields with the EAD fields. The lack of documentation on this process presented difficulties, solved only with the active support of WP10 and especially of our colleagues at Ontotext. The process involved some trial and error at the beginning and end phases.
After the rules were implemented, the data conversion was very easy and, with the exception of the error in the hierarchy mentioned previously, the tool was very helpful, in the first steps, in finding mistakes in data formatting.
A further and very important advantage of using the tool is that, after the mappings have been defined, all the work can be reused in further data exports without requiring the additional effort for the curation of self-defined and implemented workflows.
EAD Publication and ingest
The EAD records were published using the Metadata Publication Tool provided by EHRI. This tool allows exposure of the EAD records for harvesting, avoiding the difficulties involved in the implementation and deployment of OAI-PMH servers or other technologies that are currently in use.
Learning to use the tool and implement the workflow took some time, but after the first successful publication of data the workflow could be easily repeated.
Vocabulary item processing
Parallel to the data conversion and publication work, we processed the vocabulary items corresponding to the export access point, to provide easy linking to the EHRI controlled vocabularies.
The work consisted of:
- Direct mapping between vocabulary items and EHRI controlled vocabularies when one to one mapping was possible. Some of the mappings were obvious and could be directly assessed, but in other cases, the review and approval of a content specialist was necessary.
- In some cases, the Yad Vashem controlled vocabularies offer a higher degree of specificity and more than one Yad Vashem term could be potentially linked to a single term of the EHRI controlled vocabularies. In these cases, we built clusters of terms and a content specialist assessed whether the cluster was correct and whether the mapping between the cluster and the EHRI term was convenient.
- Proposal of new authorities to the WP11 task “controlled vocabularies”
Lastly, we delivered the mappings to the WP11 task “controlled vocabularies” to enable the mapping of access points in the portal.
Summary and conclusions
The export of Yad Vashem metadata was a process in which five people with diverse specialities were involved. In an attempt to quantify the work, we need to take into account two factors.
Firstly, the process of designing workflows and learning how to use the tools – tools which were not yet developed in the previous version – took some time. Secondly, the work should be synchronized in a way that would allow one person to continue the work immediately after a previous person has completed his/her portion of the work. The full process took 6 months.
A large part of the work made can be reused for future exports. This, along with the expertise acquired, may result in a 50% reduction in the amount of work required for future exports.